Assumption:
m: In a hash function h : U -> [m] for some positive integer m < |U|.
n: set of data for insertion
- If m > n then insert/delete/query take O(1) expected time.
- Requires two O(lg n)-independent hash functions, h1 and h2. (OPEN: same bound using only O(1)-independent hash family)
Why is Cuckoo Hashing cool?
For hash table:
Average Case Worst Case
Perfect hashing guarantees
n: set of data for insertion
- If m > n then insert/delete/query take O(1) expected time.
- Requires two O(lg n)-independent hash functions, h1 and h2. (OPEN: same bound using only O(1)-independent hash family)
Why is Cuckoo Hashing cool?
For hash table:
Average Case Worst Case
| Space | O(n)[1] | O(n) |
|---|---|---|
| Search | O(1) | O(n) |
| Insert | O(1) | O(n) |
| Delete | O(1) | O(n) |
Perfect hashing guarantees
- O(1) lookup
- O(1) insert
Cuckoo hashing also guarantees
- O(1) lookup**
- O(1) insert**
** O(1) expected time for insert
O(1) worst case time for query/delete: because x is either at T[h1(x)] or at T[h2(x)] ), query/delete takes worst-case two probes.
O(1) worst case time for query/delete: because x is either at T[h1(x)] or at T[h2(x)] ), query/delete takes worst-case two probes.
It is based on the collision strategy for cuckoo hashing:
Suppose we have TWO hash tables T1, T2. They each have a hash function ℎ1 (x),ℎ2 (x).
We prefer T1, but if we have to move we’ll go to T2 ;
Likewise, if we’re in T2 and have to move, we’ll go back to T1
1. Compute h1(x),
2. If T[h1(x)] is empty, we put x there, and we are done.
Otherwise, if y 2 T[h1(x)], we evict y and put x in T[h1(x)].
3. We find a new spot for y by looking at T[h2(y)] (the one that is not occupy by x).
4. Repeat this process until insert success, or after 6 lg n steps stop and rehash
Key observation: our functions are O(lg n)-independent so we can treat them as truly random functions.
1. Compute h1(x),
2. If T[h1(x)] is empty, we put x there, and we are done.
Otherwise, if y 2 T[h1(x)], we evict y and put x in T[h1(x)].
3. We find a new spot for y by looking at T[h2(y)] (the one that is not occupy by x).
4. Repeat this process until insert success, or after 6 lg n steps stop and rehash
Key observation: our functions are O(lg n)-independent so we can treat them as truly random functions.





It is Different from linear probing, open addressing and trees.
Why two tables?
Two tables, one for each hash function
Simple to visualize, simple to implement
But, why two? One table works just as well!
Just as simple to implement (all one table)


Graph Representation
1. Nodes are every possible table entry
2. Edges are inserted entries
- This is a directed graph
- Direction from current location TO alternate location

Infinite Loop:
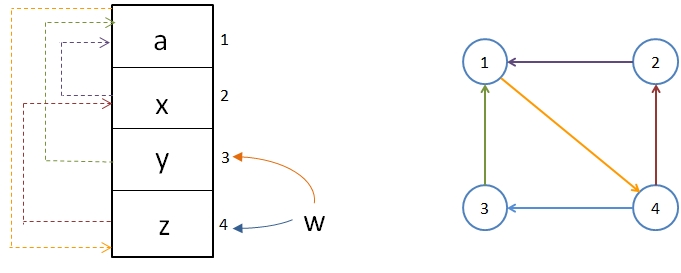
Analysis: Loops
In the graph, this is a closed loop
- We might forever re-do the same displacements
The probability of getting a loop increases dramatically once we’ve inserted N/2 elements
- N is the number of buckets (size of table)
- This is from the research on cuckoo hashing
What can we do once we get a loop?
- Rebuild, same size (ok solution)
- Double table size (better solution)
We’ll need new hash functions for both.
Lookup has O(1) time:
Because it is at most two places to look, one location per hash function
lookup(x)
return T[h1(x)] == x or T[h2(x)] == x
*deletion follows the same sequence.
Insert has amortized O(1) time:
Think of this as “in the long run”,
if you do many insertions, average time taken per insertion is also O(1).
In practice we see O(1) time insert.
insert(x)
if lookup(x)
return; // if it’s already here, done
pos <- h1(x); // store h1(x)
for i <- 1 to M // loop at most M times
if T[pos] empty T[pos] <- x
return; // if T[pos] empty, done
swap x and T[pos]; // put x in T[pos]
if pos == h1(x) // now we’re displacing
pos <- h2(x)
else
pos <- h1(x)
rehash(); // if we couldn’t stop, rehash
insert(x); // then insert currently displaced
end
Analysis: Load Factor
What is load?
The average fill factor (% full) the table is
What about cuckoo hash tables?
For two hash functions, load factor ≈50%
For three hash functions, we get ≈91%

Of course, adding of hash function and cell capacity would increase the cost penalty per one operation.
沒有留言:
張貼留言